Why This Scenario?
What if we built superintelligent tools instead of superintelligent agents, and still got the future we’re hoping for? 1Aguirre, A. (2025). Keep the Future Human. [Essay]. https://keepthefuturehuman.ai/ 2Drexler, K.E. (2019). Reframing Superintelligence: Comprehensive AI Services as General Intelligence. Future of Humanity Institute Technical Report #2019-1. https://www.fhi.ox.ac.uk/reframing-superintelligence.pdf 3Bengio, Y. et al. (2025). Superintelligent Agents Pose Catastrophic Risks: Can Scientist AI Offer a Safer Path? arXiv:2502.15657. https://arxiv.org/abs/2502.15657
This scenario is not a prediction. It’s a story, a glimpse of one possible future we could build, if we scaled and steered AI as a tool: powerful, fast, interpretable, but narrow and with limited agency. In this world, AI transforms science, healthcare, education, and governance. Not by replacing humans, but by helping us solve problems faster and more wisely.
Nearly every expert interviewed for this project preferred this kind of “Tool AI” future, at least for the near term, yet few believe we’re currently on a path that makes it likely. The incentives driving AI today point in a different direction. In this work we ask: what would it take to change that?
Alongside the story, you’ll find short explainers and examples of tools, systems, and institutions that could support this world, as well as the tensions and trade-offs it would involve. The goal isn’t to predict the most likely future, but to make this kind of future easier to imagine, talk about, and work toward (if we choose to). This scenario is complementary to other beneficial AI futures, such as the d/acc (decentralized, democratic, differential, defensive acceleration) approach. While Tool AI focuses on constraining agency (building very intelligent systems that remain under human control), d/acc focuses on constraining centralization. Both prioritize human agency over AI autonomy, but address different dimensions of risk, Tool AI through limiting system independence, d/acc through distributing control across many actors.
Scenario Premise: Tool AI 2035
This scenario imagines a world where a century’s worth of progress happens in ten years, not through superintelligence or autonomy, but by scaling and steering Tool AI:
Advanced, controllable AI systems, often narrow in scope, that assist humans without acting independently. By 2035, AI has transformed science, education, medicine, and governance. These systems are embedded into institutions and workflows as high-speed, low-risk amplifiers of human capacity.
Tool AIs helped humanity reach breakthrough after breakthrough; in energy, healthcare, climate modeling, materials science, and space exploration.
But this world is also strained:
- Tool AI has dramatically reduced employment in several knowledge work sectors.
- Incentives to diffuse Tool AI benefit remain difficult, some areas like curing cancer and accelerating cheap, ubiquitous energy have been achieved, but other solvable challenges without strong market incentives like poverty, individualized education, and agriculture remain unsolved
- Wealth and opportunity are unevenly distributed, some groups benefit massively, while others are locked out.
- There’s pressure to “just add agency” for efficiency, especially in militarized and high-risk zones.
What is Tool AI?
Tool AI in this scenario refers to artificial intelligence systems that demonstrate high task competence (intelligence) but are deliberately designed to remain controllable, with limited autonomy and often narrow scope. Unlike Artificial General Intelligence (AGI), which combines intelligence, autonomy, and generality, and thus poses more complex safety and coordination risks, Tool AI systems operate without independent goals or open-ended decision-making across domains.
This distinction is helpfully visualized in the “AGI shield diagram” developed by Anthony Aguirre in the Keep The Future Human:
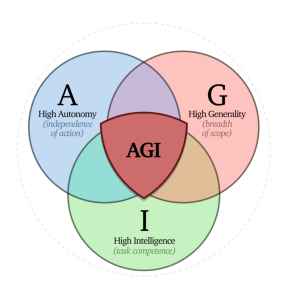
- A = Autonomy (independence of action)
- G = Generality (breadth of scope)
- I = Intelligence (task competence)
While any point on this diagram could theoretically be designed as a tool, it becomes increasingly difficult to maintain meaningful control as systems gain more autonomy (A) and generality (G). The most reliably “tooly” systems tend to be narrow and non-autonomous, so high intelligence (I) but constrained in scope and self-direction.
Liability frameworks targeting the triple intersection could create strong incentives for Tool AI approaches. Such frameworks would impose strict liability, including personal criminal liability for executives, on systems that combine high autonomy, generality, and intelligence, while providing “safe harbor” protections for systems that lack one or more of these properties. The riskier the configuration, the higher the legal exposure. If implemented, such frameworks would make Tool AI not just the safer choice, but potentially the only economically viable one for high-stakes applications.
The Tool AI systems described in this scenario deliberately occupy these liability safe harbors. A narrow diagnostic AI avoids enhanced liability despite high intelligence. A general but passive research assistant qualifies for fault-based rather than strict liability. A capable but limited personal AI companion sits safely outside the triple intersection that triggers maximum legal exposure.
The key insight isn’t that Tool AI must stay in the “I” zone, but that as capabilities increase, control mechanisms must scale proportionally. A highly general and somewhat autonomous system could still be a “tool” if it has robust oversight, clear limitations, and genuine human control, but this becomes exponentially harder to achieve and verify.
By prioritizing narrow intelligence over general-purpose autonomy, Tool AI enables us to steer progress in science, health, education, governance, and more, without giving up oversight or control.
- 1Aguirre, A. (2025). Keep the Future Human. [Essay]. https://keepthefuturehuman.ai/
- 2Drexler, K.E. (2019). Reframing Superintelligence: Comprehensive AI Services as General Intelligence. Future of Humanity Institute Technical Report #2019-1. https://www.fhi.ox.ac.uk/reframing-superintelligence.pdf
- 3Bengio, Y. et al. (2025). Superintelligent Agents Pose Catastrophic Risks: Can Scientist AI Offer a Safer Path? arXiv:2502.15657. https://arxiv.org/abs/2502.15657